Hydrological modeling with a simple LSTM network of 30 units
Abstract
Are neural networks the future of hydrological modeling? Maybe. This simple LSTM is in many ways a poor model; yet, it performs remarkably well. On the small 15-year dataset included, it archives a Nash–Sutcliffe efficiency/R2 of 0.74 on the 3-year validation part (where 0.00 is the trivial mean prediction and 1.00 is perfect prediction). On the same validation set, my own HBV implementation, SwiftHBV, archives 0.78. It still much left to beat HBV, especially its robustness. However, LSTM was never designed for numerical predictions. Its range contrained units and non-conserved water flow, makes it unnecessary hard to learn hydrological behavior. A special designed RNN architecture might perform a lot better.
1 Introduction
There have been some papers out there that have tried to model rainfall-runoff and sometimes snow storage with LSTM neural networks. For instance Kratzert et al. (2018)1 who archives a median Nash–Sutcliffe efficiency/R2 of 0.65 on 250 catchments in the US, -0.03 less than a traditional SAC-SMA+SNOW17 model. The results seem good, but not jet as good as old fashion models, like SAC-SMA+SNOW17 or HBV, which also are more robust.
This was a quick model I through together to see for myself how good these models perform compare to HBV. In difference to HBV, this model has no catchment parameters and generally no assumptions about the world. It should, therefore, be harder to fit than HBV—especially for small datasets, like the one I used. On the other hand, are they not constrained by HBV’s simplistic model of the world.
A poor model
I many ways are LSTM networks a poor model for hydrology. LSTM was created to model more fuzzy binary problems like natural language processing. While the memory cells can have arbitrary values, the inputs/outputs to/from them are constrained to the [-1, 1] domain with tanh activation functions. To be able to handle rare floods, hydrological models should not constraint large inputs or outputs.
The second problem is that LSTM has forget gates and add/subtract gates. Generally, we would like to have models where water is passed around from input, to different internal (storage) cells, between (storage) cells and then to output, without water being created or lost, except for the correction of precipitation at the input and a separate evaporation output that could be monitored.
These problems do not make LSTM inherently unusable. LSTMs are general computation machines that should theoretically be able to compute anything, given enough units. The problem is just that they might be unnecessary hard to train.
2 Method
2.1 Model
The model is a simple LSTM with one layer and 30 units, plus one output layer with ReLU activation.
2.2 Code
Code and data can be found on Github.
2.3 Optimization
- Adam is used for optimization with a learning rate of 0.00001
- The sequence length is 30 time steps (days) and batch size 1. Thus the error is back propagated 30 time steps and parameters are updated without batching.
- The internal state is reset every epoch (12 years). It can therefore learn dependencies longer than 30 days.
- The loss function is mean squared error on the discharge. There is no explicit optimization of the accumulated discharge.
2.4 Dataset
I used a short 15-years dataset from Hagabru, a discharge station in the Gaula river system, south of Trondheim (Norway). This catchment has a big area of 3059,5 km2 and no lakes to dampen responses. The first 12-years are used as training set, the last 3 years as validation set.
3 Results
3.1 Training experience
- Normalize inputs and outputs between 0.0–1.0 seems to have a big effect on how fast optimization converges, but not prediction performance. Since the LSTM layers outputs are between -1 to +1, the dense layer has to increase their weights. It seems to take a lot of time before these weights are fully learned.
- Increasing the number of LSTM-units seems to have a modest effect on performance after 30 neurons on the small dataset.
- Two LSTM-layers gave the same fit on the training set and slightly worse on the validation set. It might increase a bit with a bigger dataset, but I don’t think it is very beneficial with many layers for hydrological models.
- Normal SGD Nesterov with momentum seems to converge extremely poorly compared with Adam. I have no explanation for why.
- I tried to put accumulated discharge in the loss/objective/cost function, but this just led to models that cap peaks and smoothens the discharge rate. R2 was reduced to 0.54 on the validation set.
- I tried ReLU as activation function, but convergence failed and outputs produced NaNs. Not sure why, but ReLUs are uncommon for LSTM, so it might be that ReLUs make values explode and convergence unstable.
3.2 R2/Nash-Sutcliffe efficiency
| Dataset | LSTM | HBV | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Traning set | 0.82 | 0.78 | |||||||
| Validation set | 0.74 | 0.78 | |||||||
| Here 0.0 is the trivial mean prediction and 1.0 is perfect prediction | |||||||||
The LSTM network is generally not much behind the HBV model. It performs four percentage points, or 20% worse than the HBV model. However, the LSTM model is less robust. HBV performs equally well on the validation set as the training set, while the LSTM model performs 8 percentage points worse.
3.3 Training set
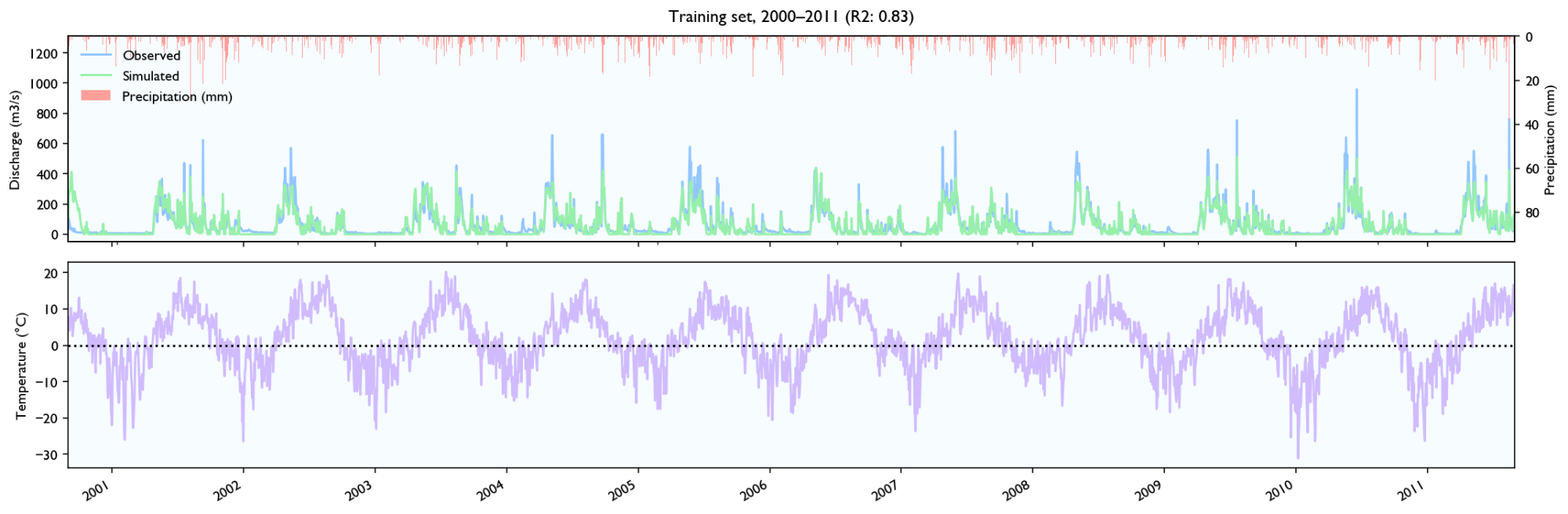
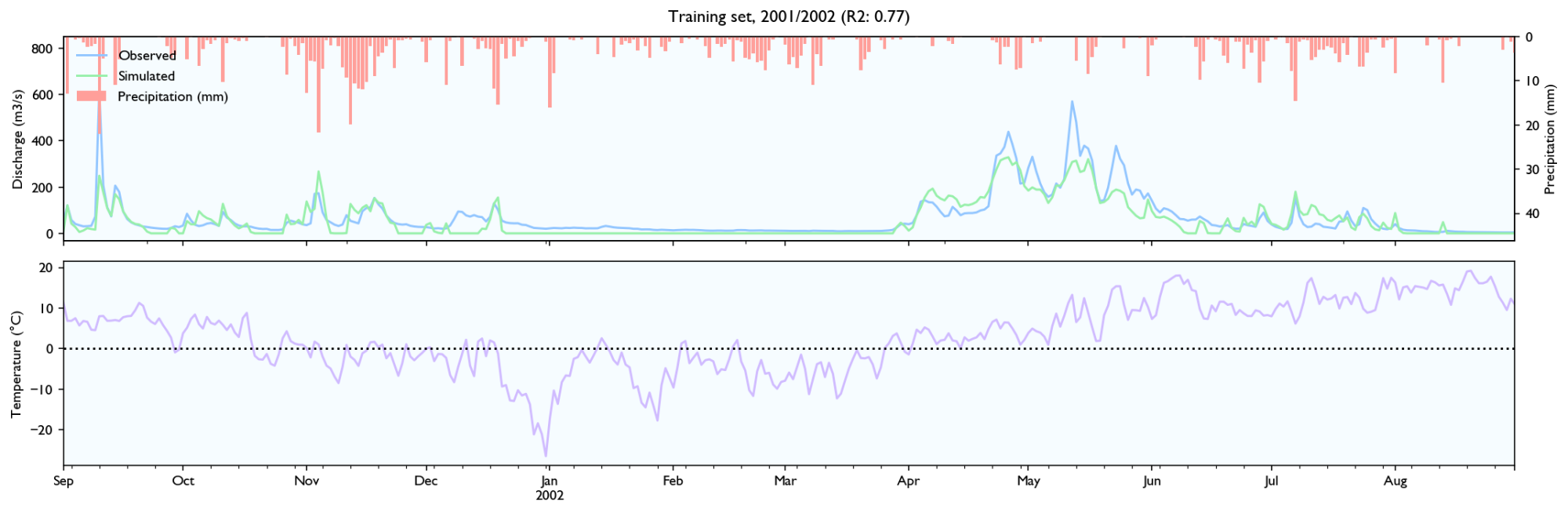
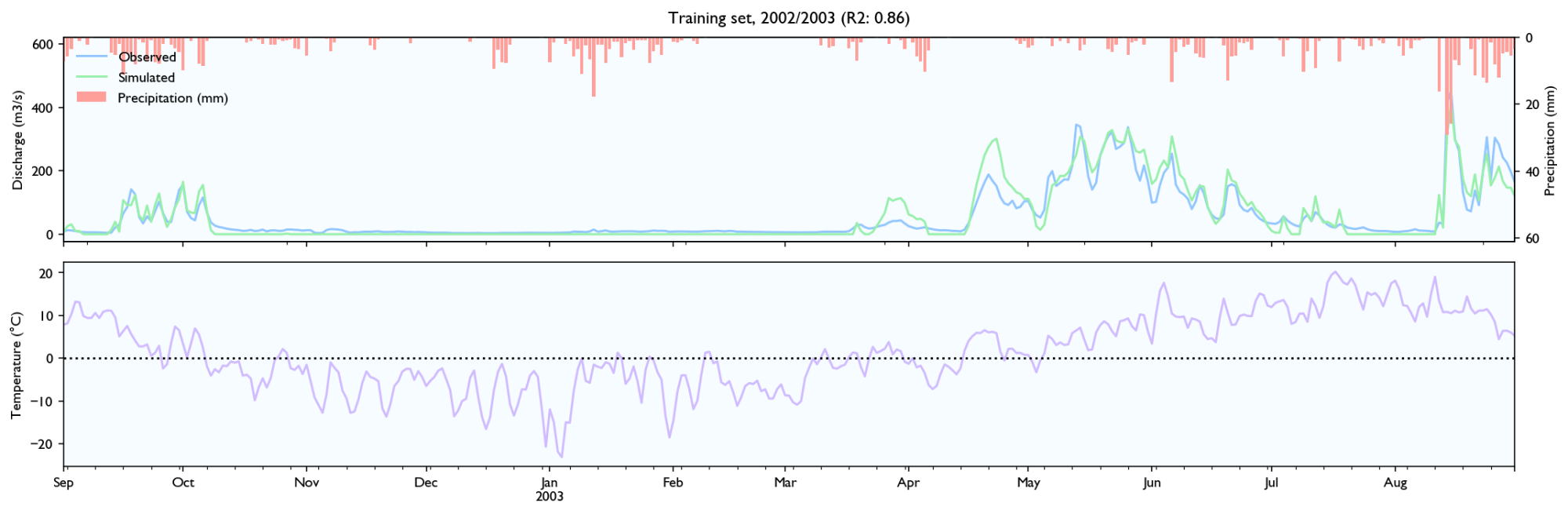
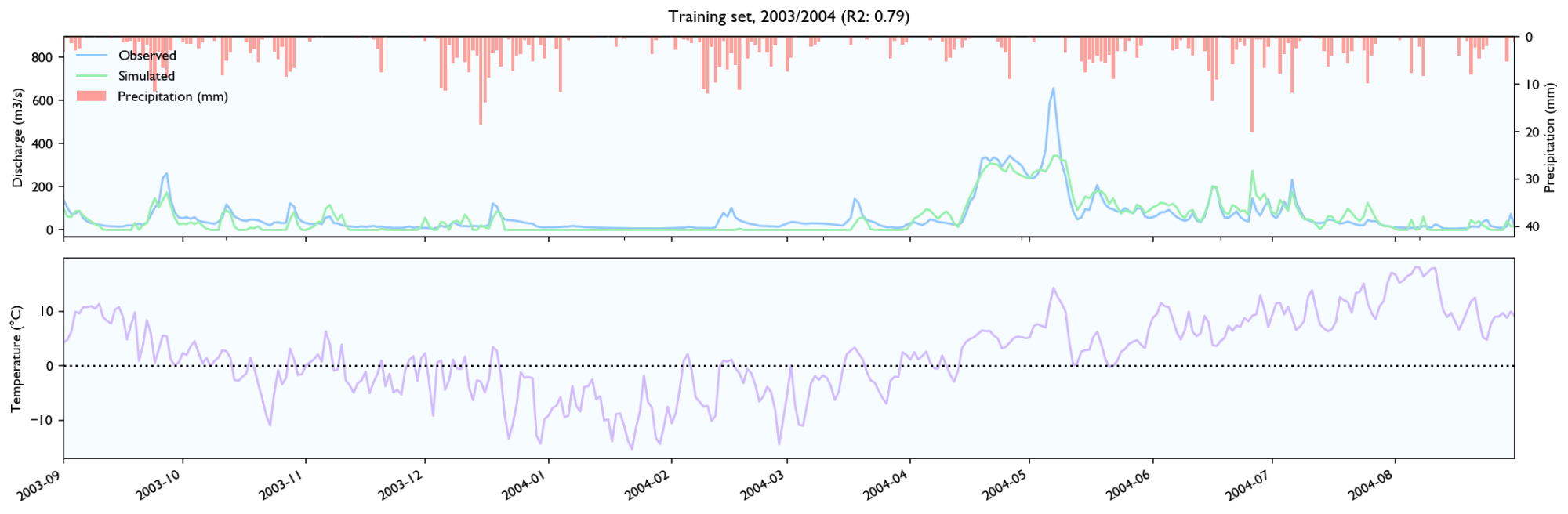

3.4 Validation set
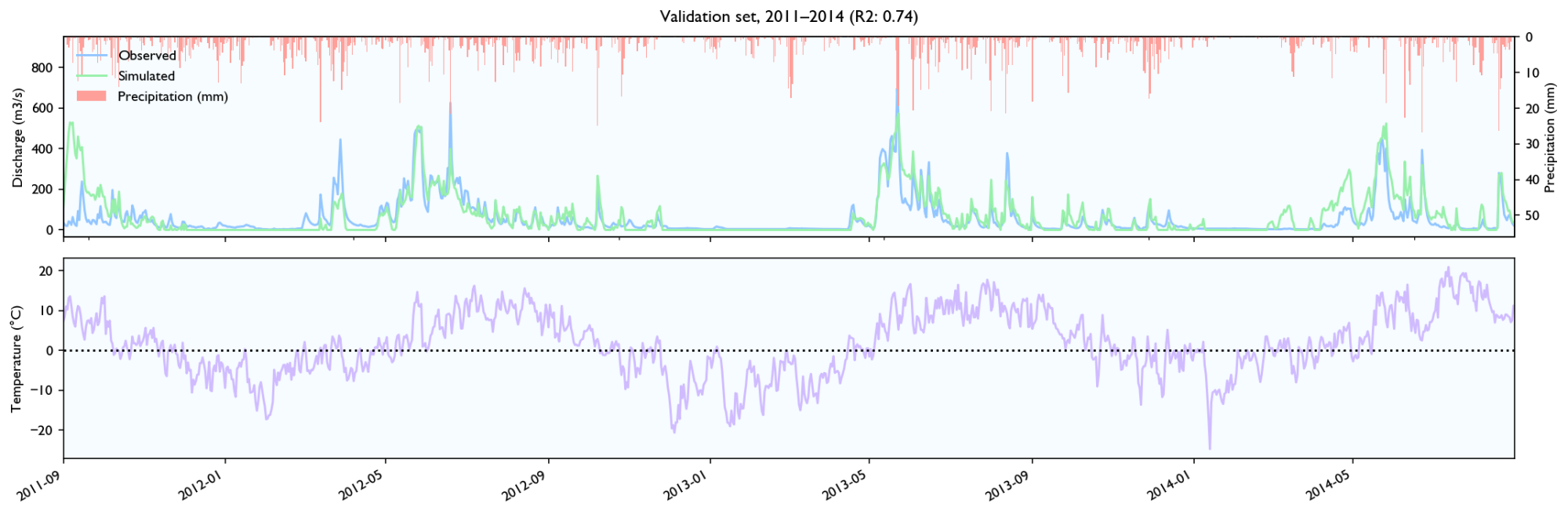
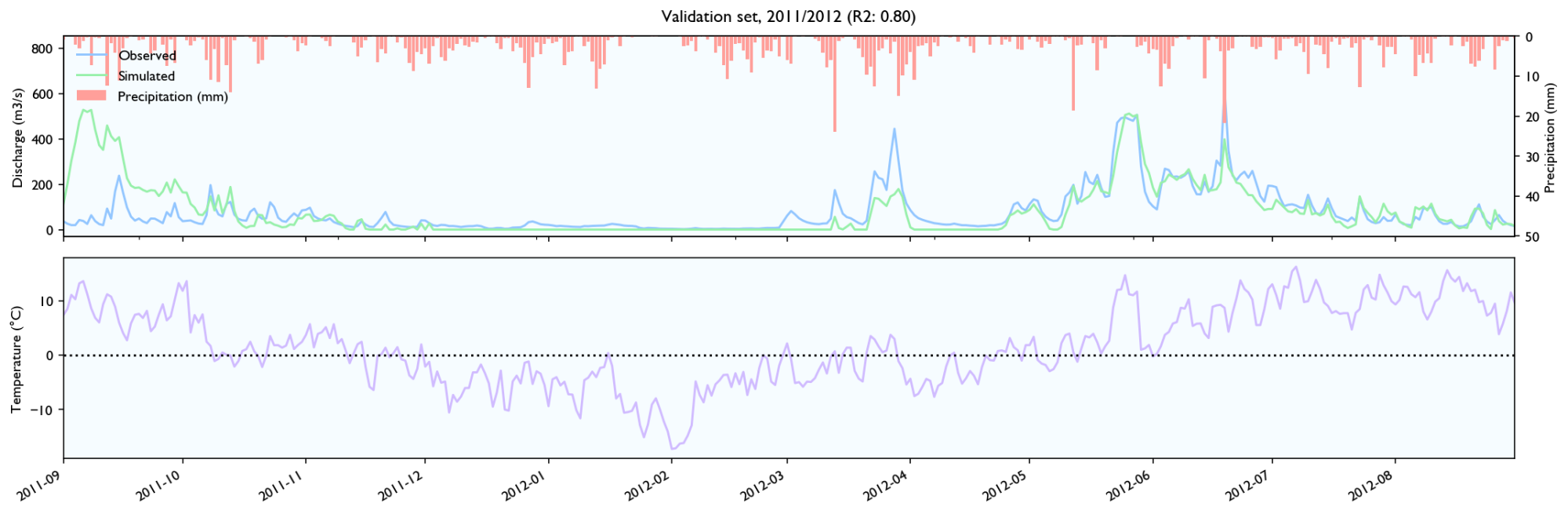
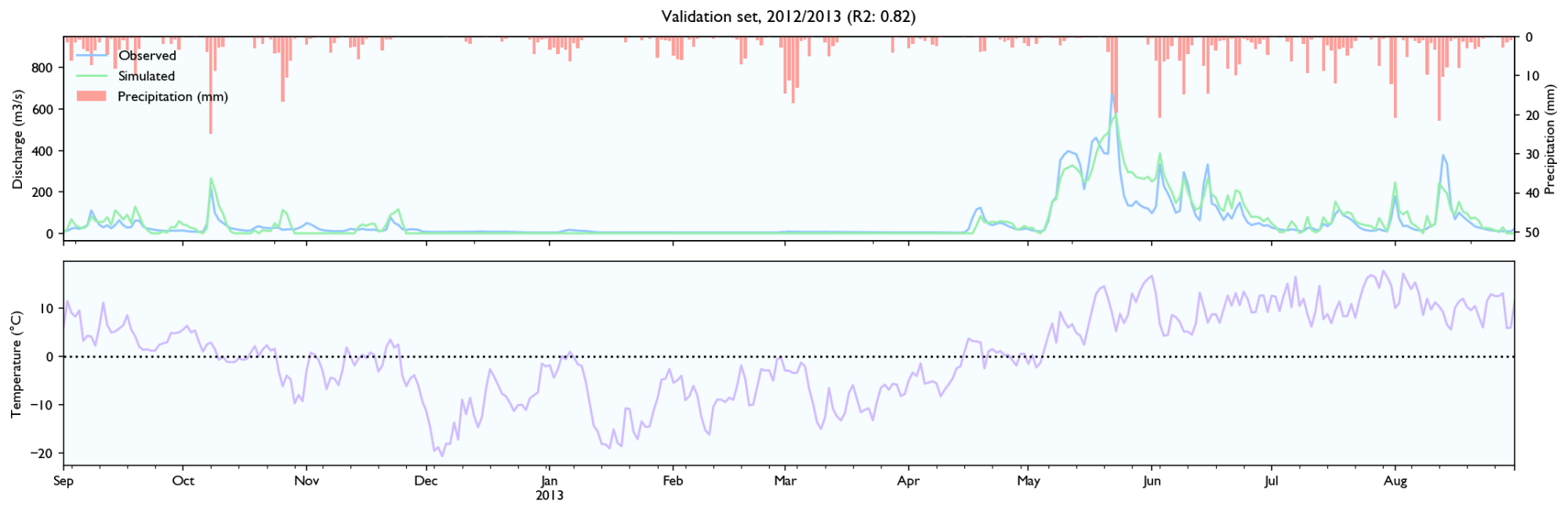
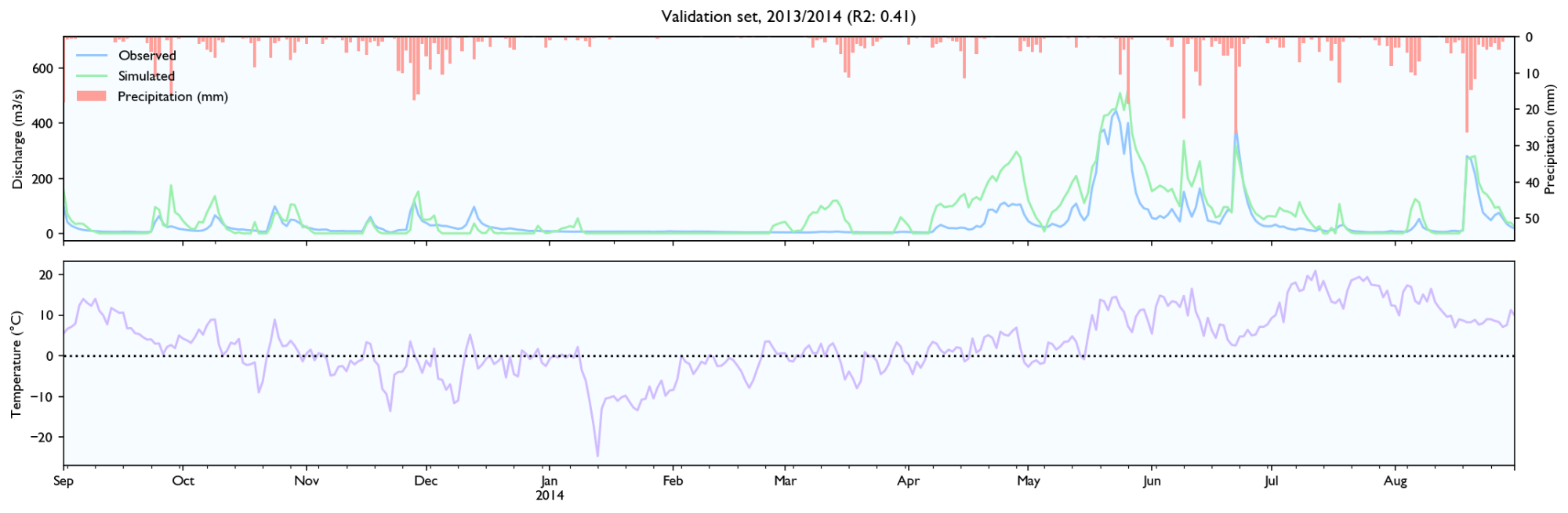

Rainfall events
- It seems to estimate the peak size after rainfall events quite well, perhaps slightly better than HBV.
- The discharge falls a bit weird. It seems to fall linearly with lots of breaks. It should fall like exponential decay, where the decay is larger for/after big rainfall events.
- It seems like the model has a maximal discharge rate. Large peaks are underestimated and simulated peaks have ca. the same value.
Snowmelt
- The model struggles with spring melt when the temperature is near zero, for instance in March and April 2014, and March 2012. When the temperature is high, like in June 2012, the estimates are good. Snowmelt around zero is something all hydrological models struggle with because snowmelt is affected not only by temperature, but also wind, humidity and in-/outgoing radiation (e.g. clear nights). It still performs worse than HBV, but the HBV is configured with the elevation distribution of the catchment and the estimated temperature on different elevations, while the LSTM-network needs to learn it, so it should perform worse.
- It seems to be able to learn to store snow, but it is hard to know how accurately it records and store snow levels. The model seems to output more water after winters with more precipitation, and it looks like the accumulated discharge is neither severely over- or underestimated during spring melt the two first years in the validation set. However, in 2014 the discharge is way too high over time.
4 Discussion
- The performance looks quite good compared to the simple, poor model and short time series. It is quite amazing how well it behaves from being trained on only 4380 time steps and that it learns quite well to store snow over long periods.
- The reason it underestimates peaks is probably because of the
tanhactivation functions. It is not the biggest problem, but it probably makes LSTM unusable to estimate (rare) flood events. A different RNN architecture could perhaps solve this. - It is hard to know how accurate the model store snow levels. However, it is probably far away from HBV. The model would likely benefit from a more constraint model when it comes to adding and subtracting water from memory cells.
- The problem that discharge rates do not smoothly decay after rainfall events, might be an artifact by how LSTM networks work. LSTM networks should be able to model exponential decay. However it requires that the cell units have values around 0.5 (so they neither are limited the tanh activation functions, or they are close to zero and produce small outputs), the activation layer needs produce outputs near 0, so the sigmoids produce output near 0.5 and decent decaying factors, and the outputs should into the forget gates on the next time step and remove the same amount of water from the cell states that was outputted. It is a lot to demand that LSTM networks should learn this accurately, and the fact that it does not look like it does might mean that LSTM networks are poor at accurately modeling snow levels, and get proper decaying outputting from storage cells.
- Even if LSTM model had performed similarly as HBV, the HBV model would be preferred. It is, of course, a lot more robust, and performs almost equally well on the validation set as the training set.
5 Conclusion
This dataset is too small to get a decent overview of LSTM s performance. However, on this dataset it performs quite well. It is not too much behind HBV, although its predictions are a lot less robust and trustwordy compare to HBV. The LSTM model fails at some places which might indicate that the architecture is not the best, like that the decaying after rainfall events are not very smooth and constrained peaks. It would be interesting to look at other RNN architectures that are more suitable for hydrological modeling.
Is it possible to create a better model?
For hydrology, we probably want an RNN network with ReLU gates and where water not lost or created. However, designing new RNN architectures is not the easiest task in the world. LSTM (and the similar GRU) has been the default architecture because it is difficult to create RNN models. LSTM was carefully designed to make training stable and avoid the vanishing gradient problem and be able to propagate errors over long time frames. I have tried to think of a better model, but probably need to think a bit more seriously, if I should have a chance.
It would also be interesting to implement HBV, or something similar, in Tensorflow and train it with gradient descent like a neural network. As far as I can see is the only strictly undifferentiable parts in HBV min/max functions, and they are differentiable in practice.
However, a pure HBV trained with gradient descent might be stuck in local minimas. Local minimas are usually not a problem for neural networks because they have lots of parameters. The chance that all second derivates are all positive is therefore small. HBV has only 16 parameters and is, therefore, more likely to be stuck in local minimas if it’s not trained by algorithms that tackle local minimas.
The ideal model might be therefore something between HBV and LSTM—a network based on HBV’s tank model, but with more parameters, more freedom, and less linearity. The error in storage cells should also be able to flow freely back in time without degradation to be able to train long term dependencies like snow storage over the winter.
References
Kratzert, Frederik, Daniel Klotz, Claire Brenner, Karsten Schulz, and Mathew Herrnegger. “Rainfall–Runoff Modelling Using Long Short-Term Memory (LSTM) Networks.” Hydrology and Earth System Sciences 22, no. 11 (November 22, 2018): 6005–22. https://doi.org/10.5194/hess-22-6005-2018. ↩
©2019 Jon Tingvold, Norway. All rights reserved.
Last updated Aug 11, 2020